Trong Chương 9, chúng ta đã giới thiệu các khái niệm về một mạng CNN bao gồm các lớp tích chập, các lớp tổng hợp và các lớp kết nối đầy đủ. Trong chương này, chúng ta sẽ xây dựng một mạng CNN đơn giản nhất để nhận dạng chữ viết tay bằng thư viện TensorFlow trong Python. Mô hình này còn được gọi là mô hình LeNET-5.
Mô hình nhận dạng chữ viết tay LeNET-5
Nguồn gốc
LeNET-5 là được mô tả bởi bài báo “Gradient-Based Learning Applied to Document Recognition” bởi các tác giả Y. Lecun, L. Bottou, Y. Bengio and P. Haffner (1998). Đây cũng là một trong những bài báo nổi tiếng trong lĩnh vực mạng thần kinh với hơn 4800 lượt trích dẫn.
Cấu trúc mạng

Cấu trúc mạng của LeNET-5 là được cho bởi Hình 10.1. Nó bao gồm hai lớp tích chập, hai lớp tổng hợp sau mỗi lớp tích chập, và hai lớp kết nối đầy đủ, được liệt kê như sau:
- Lớp đầu vào: Bộ dữ liệu đầu vào là bộ dữ liệu MNIST (xem Chương 8 để biết chi tiết).
- Lớp tích chập đầu tiên: Một ma trận 32 × 32 × 1 của một hình ảnh đen trắng (có thể là một số hoặc một chữ cái) đi qua 6 bộ lọc với tham số là f = 5, s = 1, và p = 0. Do đó ma trận thu được là 28 × 28 × 6.
- Lớp tổng hợp thứ nhất: Ma trận 28 × 28 × 6 sau đó đi quan lớp tổng hợp trung bình với tham số là f = 2 và s = 2. Kích thước ma trận lúc này giảm xuống còn 14 × 14 × 6.
- Lớp tích chập thứ hai: Ma trận 14 × 14 × 6 sau đó đi vào lớp chập thứ hai với 16 bộ lọc (tham số là f = 5, s = 1, và p = 0). Ma trận sau đó được chuyển thành 10 × 10 × 16.
- Lớp tổng hợp thứ hai: Ma trận 10 × 10 × 16 được đi qua lớp tổng hợp thứ hai với tham số là f = 2 và s = 2. Kích thước ma trận lúc này giảm xuống còn 5 × 5 × 16.
- Lớp kết nối đầy đủ thứ nhất: Ma trận 5 × 5 × 16 là được là phẳng thành 120 nơ-ron sử dụng một lớp tích chập với 120 bộ lọc (tham số là f = 5, s = 1, và p = 0).
- Lớp kết nối đầy đủ thứ hai: 120 nơ-ron ở lớp đầy đủ thứ nhất sẽ được kết nối với 84 nơ-ron ở lớp kết nối đầy đủ thứ hai.
- Lớp đầu ra: 84 nơ-ron ở lớp đầy đủ thứ hai sẽ được kết nối với một lớp ra với 10 giá trị đầu ra được gán nhãn từ 0 đến 9. Chú ý là với mục đích nhận dạng ký tự chữ số, đầu ra của lớp này sẽ là giá trị xác suất của 10 giá trị đầu ra. Ví dụ trong 10 giá trị xác suất đầu ra, giá trị xác suất cho nhãn số 7 là lớn nhất, nghĩa là bức ảnh đầu vào của chúng ta là chữ viết tay của số 7. Do đó chúng ta sẽ sử dụng một hàm kích hoạt là hàm softmax, hàm này sẽ trả về kết quả là một giá trị xác suất.
Thực hành CNN với Python
Giống như trong Chương 8, chúng ta sẽ tách mã lập trình thành từng đoạn để thảo luận cho bạn đọc dễ dàng hiểu hơn.
Các thư viện cần thiết
Đầu tiên chúng ta sẽ gọi các thư viện cần thiết để xây dựng mô hình CNN như sau:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Import the necessary packages and modules
import datetime, os
import tensorflow as tf
import matplotlib.pyplot as plt
plt.style.use('./sci.mplstyle')
from tensorflow.keras import datasets, layers, models, losses
Kết quả sẽ được thể hiện như sau
The tensorboard extension is already loaded. To reload it, use:
%reload_ext tensorboardĐọc dữ liệu
Đọc dữ liệu được cho bởi đoạn mã như sau (xem thêm Chương 8 để hiểu chia tiết các đoạn mã lệnh):
# Read MNIST dataset
(x_train, y_train), (x_test, y_test)=tf.keras.datasets.mnist.load_data()
print('Train shape:', x_train.shape)
print('Train samples:', x_train.shape[0])
print('Test samples:', x_test.shape[0], )
print('Image shape:', x_train[0].shape)
Mã trên sẽ tự động tải xuống và đọc bộ dữ liệu MNIST. Thông tin của dữ liệu là được xuất ra màn hình như sau:
Train shape: (60000, 28, 28)
Train samples: 60000
Test samples: 10000
Image shape: (28, 28)Hiệu chỉnh, chuẩn hóa và phân tách dữ liệu
Như chúng ta thấy rằng dữ liệu đầu vào cho mô hình LeNet-5 gốc là một ma trận có kích thước là 32 × 32 điểm ảnh. Do đó chúng ta cần mở rộng kích thước của ma trận đầu vào từ 28 × 28 thành 32 × 32 bằng việc thêm vào một vùng đệm (xem Chương 9). Ngoài cần hiệu chỉnh dữ liệu như được mô tả trong Chương 8 như sau:
# Add pad to extend size for input matrix
x_train = tf.pad(x_train, [[0, 0], [2,2], [2,2]])/255
x_test = tf.pad(x_test, [[0, 0], [2,2], [2,2]])/255
x_train.shape
Chúng ta sẽ thu được ma trận như sau:
TensorShape([60000, 36, 36])Như thảo luận trong Chương 9, chúng ta cần thiết lập dữ liệu trong ba chiều, trong đó chiều thứ ba được xác định bởi các kênh. Do các bức ảnh của chúng ta là hình đen trắng, do đó chúng ta chỉ có một kênh. Đoạn mã thêm chiều thứ 3 vào ma trận dữ liệu đầu vào như sau:
# Add dimension for input matrix
x_train = tf.expand_dims(x_train, axis=3, name=None)
x_test = tf.expand_dims(x_test, axis=3, name=None)
x_train.shape
Kết quả ma trận thu được trong ba chiều như sau:
TensorShape([60000, 36, 36, 1])Tiếp theo chúng ta cần một bộ dữ liệu xác thực. Bộ dữ liệu này bao gồm 2,000 bức ảnh, được tách ra từ bộ dữ liệu huấn luyện như sau:
# Validation data extraction
x_val = x_train[-2000:,:,:,:]
y_val = y_train[-2000:]
x_train = x_train[:-2000,:,:,:]
y_train = y_train[:-2000]
Xây dựng mô hình LeNET-5
Như được thảo luận bên trên về cấu trúc của một mô hình LeNET-5 (xem Hình 9.1). Mã lập trình để xây dựng một mô hình LeNET-5 là như sau:
# Build the CNN model
model = models.Sequential()
model.add(layers.Conv2D(6, 5, activation='tanh', input_shape=x_train.shape[1:]))
model.add(layers.MaxPool2D(2))
model.add(layers.Activation('sigmoid'))
model.add(layers.Conv2D(16, 5, activation='tanh'))
model.add(layers.MaxPool2D(2))
model.add(layers.Activation('sigmoid'))
model.add(layers.Conv2D(120, 5, activation='tanh'))
model.add(layers.Flatten())
model.add(layers.Dense(84, activation='tanh'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
Chúng ta sử dụng ba lớp tích chập có kích thước bộ lọc là 5 × 5, và số bộ lọc lần lượt là 6, 16, 120. Chú ý là thay vì là phẳng ở lớp tổng hợp thứ 2 và sử dụng một lớp kết nối đầy đủ với 120 nơ-ron, chúng ta sử dụng một lớp tích chập với 120 bộ lọc 5 × 5. Chúng ta sẽ sử dụng hai lớp tổng hợp với kiểu tổng hợp là giá trị lớn nhất và kích thước ma trận là 2 × 2. Kết quả sẽ được là phẳng ở lớp tích chập thứ ba và kết nối với một lớp kết nối đầu đủ với 84 nơ-ron. Cuối cùng là lớp đầu ra với 10 giá trị đầu ra. Chúng ta sử dụng hàm tanh (xem Chương 3) là hàm kích hoạt cho các lớp tích tụ và lớp kết nối đầu đủ, hàm sigmoid cho các lớp tổng hợp, và hàm softmax cho lớp đầu ra. Với mô hình như trên, chúng ta sẽ có tổng số là 61,706 cần được huấn luyện và tối ưu.
Kết quả của mô hình trên là được xuất ra màn hình như sau:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 156
max_pooling2d (MaxPooling2D (None, 14, 14, 6) 0
)
activation (Activation) (None, 14, 14, 6) 0
conv2d_1 (Conv2D) (None, 10, 10, 16) 2416
max_pooling2d_1 (MaxPooling (None, 5, 5, 16) 0
2D)
activation_1 (Activation) (None, 5, 5, 16) 0
conv2d_2 (Conv2D) (None, 1, 1, 120) 48120
flatten (Flatten) (None, 120) 0
dense (Dense) (None, 84) 10164
dense_1 (Dense) (None, 10) 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0Cấu hình, lưu trữ và huấn luyện LeNET-5
Mô hình LeNET-5 được cấu hình và huấn luyện bởi đoạn mã sau:
# Configures the CNN model for training
model.compile(optimizer='adam', loss=losses.sparse_categorical_crossentropy, metrics=['accuracy'])
# Store log for TensorBoard
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
# Training the CNN model with the given inputs
history = model.fit(x=x_train, y=y_train, batch_size=64, epochs=20, validation_data=(x_val, y_val), callbacks=[tensorboard_callback])
Chúng ta sử dụng thuật toán adam và hàm lỗi sparse categorical cross-entropy. Độ chính xác của mô hình là được được lưu vào biến “accuracy”. Mô hình sẽ được huấn luyện với 20 bước (epochs=20) và một tệp bao gồm 64 bức ảnh (batch_size=64) là lần lượt được đưa vào quá trình huấn luyện. Các bước tính toán cũng được lưu trữ tại thư mục logs với tên thư mục là năm, tháng, ngày – thời gian. Thư mục logs này sẽ được sử dụng để trực quan hóa với TensorBoard.
Kết quả của các bước huấn luyện sẽ được xuất ra ngoài màn hình như sau:
Epoch 1/20
907/907 [==============================] - 16s 17ms/step - loss: 1.6318 - accuracy: 0.3951 - val_loss: 0.3101 - val_accuracy: 0.9125
Epoch 2/20
907/907 [==============================] - 21s 23ms/step - loss: 0.2744 - accuracy: 0.9147 - val_loss: 0.1495 - val_accuracy: 0.9595
Epoch 3/20
907/907 [==============================] - 16s 18ms/step - loss: 0.1897 - accuracy: 0.9393 - val_loss: 0.1488 - val_accuracy: 0.9565
Epoch 4/20
907/907 [==============================] - 17s 18ms/step - loss: 0.1474 - accuracy: 0.9540 - val_loss: 0.1011 - val_accuracy: 0.9735
Epoch 5/20
907/907 [==============================] - 17s 19ms/step - loss: 0.1303 - accuracy: 0.9592 - val_loss: 0.0879 - val_accuracy: 0.9755
Epoch 6/20
907/907 [==============================] - 17s 19ms/step - loss: 0.1177 - accuracy: 0.9630 - val_loss: 0.0817 - val_accuracy: 0.9765
Epoch 7/20
907/907 [==============================] - 17s 18ms/step - loss: 0.1078 - accuracy: 0.9650 - val_loss: 0.0988 - val_accuracy: 0.9775
Epoch 8/20
907/907 [==============================] - 17s 19ms/step - loss: 0.1016 - accuracy: 0.9676 - val_loss: 0.0902 - val_accuracy: 0.9695
Epoch 9/20
907/907 [==============================] - 18s 20ms/step - loss: 0.0924 - accuracy: 0.9709 - val_loss: 0.0864 - val_accuracy: 0.9780
Epoch 10/20
907/907 [==============================] - 16s 18ms/step - loss: 0.0895 - accuracy: 0.9717 - val_loss: 0.0842 - val_accuracy: 0.9795
Epoch 11/20
907/907 [==============================] - 17s 18ms/step - loss: 0.0845 - accuracy: 0.9729 - val_loss: 0.0722 - val_accuracy: 0.9775
Epoch 12/20
907/907 [==============================] - 15s 17ms/step - loss: 0.0810 - accuracy: 0.9745 - val_loss: 0.0724 - val_accuracy: 0.9800
Epoch 13/20
907/907 [==============================] - 17s 19ms/step - loss: 0.0778 - accuracy: 0.9750 - val_loss: 0.0713 - val_accuracy: 0.9835
Epoch 14/20
907/907 [==============================] - 19s 21ms/step - loss: 0.0748 - accuracy: 0.9760 - val_loss: 0.0621 - val_accuracy: 0.9835
Epoch 15/20
907/907 [==============================] - 16s 18ms/step - loss: 0.0712 - accuracy: 0.9769 - val_loss: 0.0562 - val_accuracy: 0.9830
Epoch 16/20
907/907 [==============================] - 16s 17ms/step - loss: 0.0691 - accuracy: 0.9778 - val_loss: 0.0817 - val_accuracy: 0.9820
Epoch 17/20
907/907 [==============================] - 20s 21ms/step - loss: 0.0633 - accuracy: 0.9795 - val_loss: 0.0717 - val_accuracy: 0.9830
Epoch 18/20
907/907 [==============================] - 20s 22ms/step - loss: 0.0622 - accuracy: 0.9804 - val_loss: 0.0597 - val_accuracy: 0.9865
Epoch 19/20
907/907 [==============================] - 19s 21ms/step - loss: 0.0632 - accuracy: 0.9792 - val_loss: 0.0514 - val_accuracy: 0.9890
Epoch 20/20
907/907 [==============================] - 19s 21ms/step - loss: 0.0595 - accuracy: 0.9809 - val_loss: 0.0610 - val_accuracy: 0.9820Vẽ đồ thị với Matplotlib
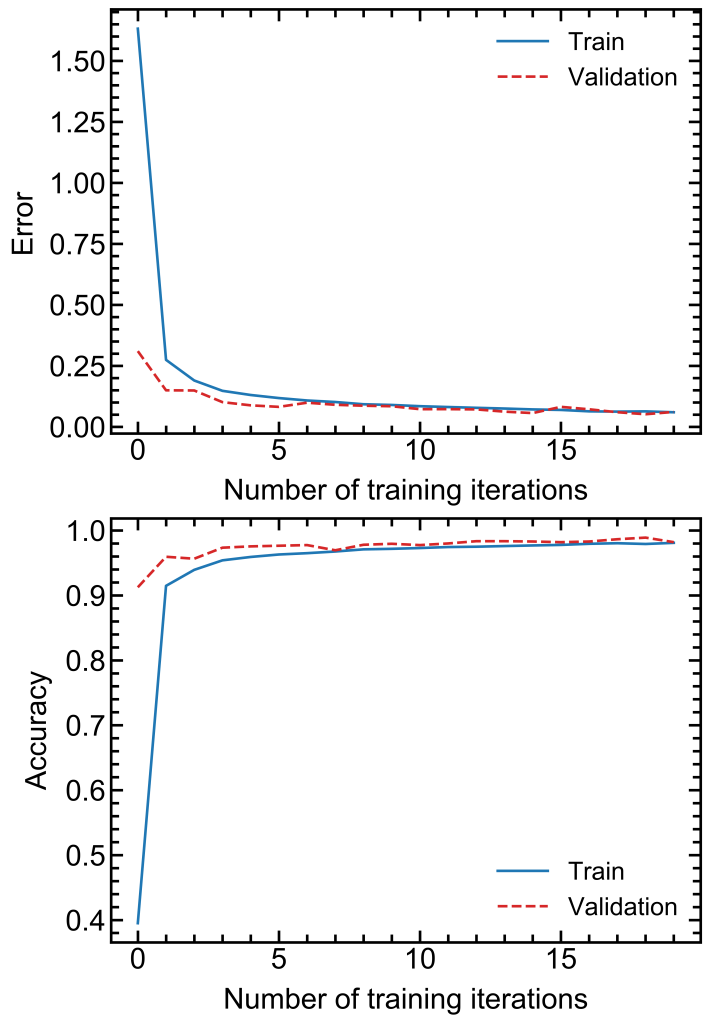
Các kết quả đầu ra là được lưu trong biến “history” từ dòng lệnh trên, do đó chúng ta có thể vẽ đồ thị với thư viện Matplotlib cho lỗi và độ chính xác như sau:
# Plot results with Matplotlib
fig, axs = plt.subplots(2, 1, figsize=(8,13))
axs[0].plot(history.history['loss'])
axs[0].plot(history.history['val_loss'],ls='--')
axs[0].set_xlabel('Number of training iterations')
axs[0].set_ylabel('Error')
axs[0].legend(['Train', 'Validation'])
axs[1].plot(history.history['accuracy'])
axs[1].plot(history.history['val_accuracy'],ls='--')
axs[1].set_xlabel('Number of training iterations')
axs[1].set_ylabel('Accuracy')
axs[1].legend(['Train', 'Validation'])
# Show figure
plt.savefig('LeNet5.png', format="png", dpi=600)
plt.show()
Các bạn sẽ thu được kết quả như trong Hình 10.2. Có thể thấy rằng, sau 10 bước huấn luyện kết quả đã có thể hội tụ với lỗi tiến về 0 và độ chính xác là 98%.
Kiểm tra độ chính xác với mô hình đã được huấn luyện
Để kiểm tra độ chính xác của một mô hình đã được huấn luyện, các bạn đơn giản là sử dụng mã lập trình sau:
# Evaluating the already trained CNN model using the test data
model.evaluate(x_test, y_test)
Kết quả sẽ xuất ra màn hình như sau (với lỗi là 0.0607 và độ chính xác là 0.9817):
313/313 [==============================] - 3s 10ms/step - loss: 0.0607 - accuracy: 0.9817
[0.060676831752061844, 0.9817000031471252]Trực quan hóa mô hình và kết quả bằng TensorBoard
Công cụ trực quan TensorBoard được sử dụng thông qua lệnh sau:
# Show data with TensorBoard
%tensorboard --logdir logs
Một giao diện người dùng trực quan sẽ được hiển thị trên cửa sổ của JupyterLab như sau:

Bài tập tự thực hành
- Xây dựng một mô hình LeNET-5 cho bộ dữ liệu ảnh màu với bộ dữ liệu CIFAR-10. Dữ liệu CIFAR-10 có thể được tự động tải thông qua lệnh “(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()”. Thư viện CIFAR-10 bao gồm 60,000 bức ảnh màu có kích thước ma trận trong ba chiều là 32 × 32 × 3.
